介绍
很多人在开始Faceswapping时不知所措,并且犯了许多错误。错误是好的。这是我们的学习方式,但是有时在深入研究之前可能会有所帮助。 在本文中,我将详细介绍我们如何训练模型。有几种型号有很多选择。我不会掩盖一切,但希望这能给您足够的知识来做出自己的明智决定。如果您尚未生成用于训练的面部表情,请立即停止并转到提取教程立即生成它们。 本教程中有很多背景信息。我建议您熟悉这一切。机器学习是一个复杂的概念,但我尝试将其分解为尽可能简单的理解。对神经网络的工作原理以及从中获得的数据类型有基本的了解,将极大地提高您成功交换数据的机会。 我将在本教程中使用GUI,但前提是cli完全相同(cli中提供了GUI中提供的所有选项)。
什么是训练?
总览
在较高的级别上,培训正在教我们的神经网络(NN)如何重塑脸部。大多数模型主要由两部分组成:
-
编码器 -这项工作的工作是将大量人脸作为输入,并将其“编码”为“矢量”形式的表示形式。重要的是要注意,它并不是在学习您输入的每张脸的确切表示,而是在尝试创建一种算法,该算法可用于以后尽可能地重建与输入图像最接近的脸。
-
解码器 -这样做的工作是获取由编码器创建的矢量,并尝试将此表示形式变回人脸,并使其与输入图像尽可能地匹配。

某些模型的构造略有不同,但基本前提保持不变。 NN需要知道它在编码和解码人脸方面做得如何。它使用2个主要工具来执行此操作:
-
损失 -对于输入模型的每批面孔,NN都会查看其尝试通过其当前的编码和解码算法重新创建的面孔,并将其与所输入的实际面孔进行比较。完成后,它将给自己一个分数(损失值)并相应地更新其权重。
-
权重 -模型评估了重建脸部的程度后,便会更新其权重。这些输入到编码器/解码器算法中。如果它在一个方向上调整了权重,但是感觉到重建脸部的工作比以前做得差,那么它就知道权重在朝错误的方向移动,因此它将以另一种方式进行调整。如果感觉有所改善,那么它将知道继续沿前进方向调整权重。

然后,该模型多次重复执行此操作,并根据其损失值不断更新其权重,从理论上讲会随着时间的推移而不断改进,直到达到您认为已学到足以有效重现脸部的程度,或者损失值停止下降为止。 现在我们有了神经网络的基本知识,以及它如何学习创建面孔,这对面孔交换有何作用?在上面的细目中,您可能已经注意到,该NN学习如何对一个人的面孔进行加载,然后重建这些面孔。这不是我们想要的……我们要承担很多的面孔并重建别人的面孔。为了实现这一目标,我们的NN做了两件事:
-
共享编码器 -训练模型时,我们将为其提供2组面孔。A集(我们要替换的原始面孔)和B集(我们要放置在场景中的交换面孔)。实现这一目标的第一步是共享A和B集的编码器。这样,我们的编码器可以为2个不同的人学习一个算法。这一点非常重要,因为我们最终将告诉我们的神经网络采用一张脸的编码并将其解码为另一张脸。因此,编码器需要查看和学习我们交换所需的两套面孔。
-
交换式解码器 -训练模型时,我们训练2个解码器。解码器A正在获取编码矢量并尝试重新创建FaceA。解码器B正在获取编码矢量并尝试重新创建FaceB。当最终交换面孔时,我们切换了解码器,因此我们将模型Face A馈给了我们,但是将其传递给解码器B。由于已经在两组面孔上训练了编码器,因此模型将对输入的A面孔进行编码,然后尝试从解码器B重构它,从而导致从模型输出交换的面孔。

术语 使用Faceswap时,您将看到一些常见的机器学习术语。为了简化生活,此处显示术语表:
-
批处理 -批处理是一组同时通过神经网络馈入的面孔。
-
批次大小 -批次大小是同时通过神经网络输入的批次的大小。批处理大小为64意味着将通过神经网络一次馈送64张脸,然后为这批图像计算损失和权重更新。较高的批次大小将训练得更快,但会导致较高的概括性。较低的批次大小将训练得较慢,但可以更好地区分面孔之间的差异。在培训的各个阶段调整批次大小会有所帮助。
-
纪元 -纪元是对通过神经网络馈送的数据的完整表示:如果您有5000个面的文件夹,则当模型看到所有5000个面时为1个纪元。当模型两次看到所有5000张面孔时,将出现2个纪元,依此类推。就Faceswap而言,Epoch实际上并不是一种有用的措施。由于模型是在2个数据集(A侧和B侧)上训练的,除非这些数据集的大小完全相同(非常不可能),所以不可能计算一个纪元,因为每个纪元都不同。
-
示例 -就Faceswap而言,示例是“ Face”的另一个名称。它基本上是一张通过神经网络传递的面孔。如果模型看到了10个示例,则它看到了10个面。
-
EG / s-这是神经网络每秒看到的示例数,或者就Faceswap而言,就是模型每秒处理的面孔数。
-
迭代 -迭代是通过神经网络处理的一个完整批处理。因此,批处理大小为64的10次迭代将意味着该模型已看到640(64 * 10)个面。
-
NN-神经网络的缩写。
训练数据
数据质量对您的模型有多重要是不可以夸大其词的。较小的模型可以对体面的数据很好地执行,类似地,没有模型可以对不良的数据执行得很好。在模型的每一侧至少应有500张变化的图像,但是,数据越多,变化越多,则越好。使用的图像数量合理,介于1,000到10,000之间。添加比这更多的图像实际上会伤害训练。 太多相似的图像将无法帮助您的模型。您需要尽可能多的不同角度,表情和照明条件。常见的误解是针对特定场景训练模型。这是“记忆”,而不是您要实现的目标。您正在尝试训练模型以在所有角度,在所有情况下使用所有表达式来理解一张脸,并在所有角度,在所有条件下使用所有表达式来与另一张脸交换它。因此,您希望从A和B集的尽可能多的不同来源构建训练集。 两侧的不同角度非常重要。神经网络只能学习所见。如果95%的面孔正对着镜头直视而5%则是侧面朝上,那么模型将需要很长时间才能学习如何在侧面上创建侧面。它可能根本无法创建它们,因为它很少能看到侧面。理想情况下,您希望脸角,表情和光照条件的分布尽可能均匀。 同样,在A侧和B侧之间具有尽可能多的匹配角度/表情/照明条件也很重要。如果A侧有很多配置文件图像,而B侧没有配置文件图像,则该模型将永远无法在配置文件中执行交换,因为解码器B将缺少创建配置文件镜头所需的信息。 培训数据的质量通常不应模糊不清,并且应具有高质量(清晰和详细)。但是,可以在训练集中包含一些模糊/部分模糊的图像。最终,在最后一次交换中,某些面孔会变得模糊/低分辨率/模糊不清,因此,对于NN来说,也必须看到这些类型的图像,以便进行忠实的娱乐,这一点很重要。 可以找到有关创建训练集的更多详细信息在摘录教程中。
选择模型
Faceswap中有几种可用的模型,并且随着时间的推移会增加更多的模型。每个人的素质都可能是高度主观的,因此,这将简要概述每个(当前)可用的人。最终,最适合您的模型可以归结为许多因素,因此没有明确的答案。每种都有优点和缺点,但是如上所述,最重要的一个因素是数据的质量。没有模型可以解决数据问题。
您将在下面看到输入和输出大小(例如64px输入,64px输出)的说明。这是输入到模型(输入)的脸部图像的大小和从模型(输出)生成的脸部的大小。馈入模型的所有脸部都是正方形,因此64px的图像将是64像素宽高64像素。一个普遍的误解是,高分辨率的输入将导致更好的交换。虽然可以提供帮助,但并非总是如此。NN正在学习如何将面部编码为一种算法,然后再次对该算法进行解码。它只需要足够的数据就可以创建可靠的算法。输入分辨率和输出质量不直接关联。
值得注意的是,模型越大,训练所需的时间就越长。原始模型在Nvidia GTX 1080上的训练可能需要12-48小时的时间。反派在相同的硬件上可能需要一周以上的时间。通常认为,输入大小加倍的模型将花费两倍的时间。这是不正确的。至少需要四倍的时间,甚至可能更长。这是因为64px图像具有4,096像素。但是,一个128像素的图像具有16,384像素。这是原来的4倍,此外,还需要扩展模型以处理不断增长的数据量,并且训练时间可以快速累积。
-
轻量级(64px输入,64px输出)-这是一种精简的模型,旨在在具有<= 2GB VRAM的GPU上运行。这不是所谓的“生产就绪”,而是使具有较低端硬件的用户可以训练模型。在高端GPU上,它将非常快速地进行训练,因此对于在过渡到更繁重的模型之前快速查看掉期可能的工作情况很有用。
-
原始(输入64px,输出64px)-启动所有模型。仍然可以提供出色的结果,并且有助于您理解数据集质量实际上是交换质量的最大驱动因素之一。
-
IAE(64像素输入,64像素输出)-一个模型,其结构与其他模型略有不同。它具有一个共享的编码器和一个共享的解码器,但是位于编码器和解码器之间的3个中间层(一层代表A,一层代表B,一层共享)。它以这种方式构造,以试图更好地分离身份。可以在此处了解有关此模型的更多信息:https://github.com/deepfakes/faceswap/pull/251
-
Dfaker(64px输入,128px输出)-此模型利用了一些与原始模型不同的技术,并且着重于将输入扩展为更高的分辨率输出。尽管存在了一段时间,该模型仍然取得了不错的结果,而缺少自定义选项使其成为一种简单的“抛弃式”模型。
-
不平衡(输入64-512px,输出64-512px)-这是一个功能强大的模型,可以通过多种方式自定义和改进模型,但是需要更多的专业知识和诀窍才能获得良好的结果。可以说已经被“ RealFace”所取代。值得注意的是,此模型将更多的重点放在B解码器上,因此反转交换(即交换B> A而不是A> B)将导致效果不理想。
-
DFL- H128(128px输入,128px输出)-该模型实际上使用与Original完全相同的编码器和解码器,但随后使用128px输入而不是64px,然后尝试将图像压缩为代表原始图像一半的人脸。与原始相比,较小的“潜在空间”在质量上有一些缺点,从而抵消了较大的输入量。
-
DFL-SAE(输入64-256像素,输出64-256像素)-此模型中包含两种不同的网络结构,一种基于原始共享编码器/分离解码器模型,另一种基于IAE模型(共享中间层)。有许多自定义选项。给出很好的细节,但可能导致某些身份流失(即,A的某些功能可能仍在B中可见)。
-
反派(128px输入,128px输出)-反派可能是最详细的模型,但VRAM 占用大量资源,并且在进行有限源训练时可以提供低于标准的颜色匹配。是病毒史蒂夫·布塞米(Steve Buscemi)/珍妮弗·劳伦斯(Jennifer Lawrence)Deepfake的来源。由于此型号没有任何自定义选项(除了低内存型号之外),如果您想要更高分辨率的型号而无需调整任何设置,这是一个不错的选择。
-
Realface(输入64-128px,输出64-256px)-不平衡模型的后继者。从该模型和Dfaker中吸取教训,同时希望进一步发展它们。该模型是高度可定制的,但是当您对自己的工作以及设置的影响有所了解时,最好对选项进行调整。与不平衡模型一样,此模型将更多的重点放在B解码器上,因此反转交换(即交换B> A而不是A> B)将导致令人满意的结果。
-
Dlight(128px输入,128-384px输出)-基于dfaker变体的高分辨率模型,着重于使用自定义的upscaler放大面部。这是最新的模型,非常易于配置。
型号配置设置
好的,您已经选择了模型,让我们开始培训吧!好吧,站在那里。我很欣赏您的渴望,但是您可能会想先设置一些特定于模型的选项。我将为此使用GUI,但是可以在faceswap文件夹中的faceswap / config / train.ini位置找到配置文件(如果使用命令行)。 由于这些模型各不相同,因此我将不涉及每个模型的选项,并且很难针对新模型进行更新,但是我将概述一些较常见的选项。我们将重点放在适用于所有模型的全局选项上。所有选项都有工具提示,因此将鼠标悬停在选项上可获得有关其功能的更多信息。 要访问模型配置面板,请转到设置 >配置火车插件...:

-
全局 这些是适用于所有模型的选项:

此页面上的所有选项(“ 学习率 ”除外)仅在创建新模型时生效。一旦开始训练模型,此处选择的设置就会“锁定”到该模型,无论您在此处进行什么设置,只要您继续训练,就会重新加载该设置。
-
适用于送入模型的人脸的人脸选项

-
覆盖率 -这是将输入模型的源图像的数量。按给定的数量从中心裁剪一定百分比的图像。覆盖率越高,就越能获得更多的面部。裁剪图像量的图示如下所示:

虽然从直觉上看,覆盖范围似乎总是更好,但实际上并非如此,这是一种折衷。虽然更高的覆盖率意味着将交换更多的人脸,但是模型的输入大小始终保持不变,因此,由于需要将更多信息打包到相同大小的图像中,因此交换的细节可能不太详细。为了说明这一点,下面是一张具有62.5%覆盖率和100%覆盖率的相同图像的极端示例,它们的大小均为32px。如您所见,100%覆盖率图像包含的细节远少于62.5%版本。最终,此选项的正确选择取决于您:

-
面罩 适用于带面罩训练的选项。

设置遮罩是一种指示图像的哪个区域很重要的方法。在下面的示例中,红色区域“被遮盖了”(即:它被认为不重要),而透明区域被“遮盖了”(这是面部,因此我们感兴趣的区域):

戴口罩进行训练有两个目的:
-
它将训练的重点放在面部区域,从而迫使模型对背景的重视程度降低。这可以帮助模型更快地学习,同时还可以确保它不会占用不重要的空间学习背景细节。
-
学习的掩码可以在转换阶段使用。在当前的实现中,学到的掩码在转换时是否比使用标准掩码有什么好处是有争议的,但是使用掩码进行训练可以确保您可以选择使用它。
注意:如果您正在使用面罩进行训练,则必须在每个输入文件夹中为A和B中的所有面部提供路线文件。
-
面罩类型 -用于训练的面罩类型。要使用遮罩,您必须已将所需的遮罩添加到路线文件中。您可以使用遮罩工具添加/更新遮罩。看到viewtopic.php?f = 5&t = 27#extract 对于每个口罩的全面描述。
-
蒙版模糊内核 -将轻微的模糊应用于蒙版的边缘。实际上,它去除了蒙版的硬边缘,并从面部到背景逐渐将其融合。这可以帮助计算不正确的蒙版。是否要启用此功能以及使用什么值取决于您自己。默认值应该没问题,但是您可以使用遮罩工具进行实验。
-
遮罩阈值 -此选项不会影响基于对齐的遮罩(扩展的组件),因为它们是二进制的(即,遮罩是“打开”还是“关闭”)。对于基于NN的蒙版,该蒙版不是二进制的,并且具有不同级别的不透明度。在某些情况下,这可能会导致面膜斑点。增大阈值将使遮罩的部分接近透明,完全透明,而使遮罩的部分接近实体,完全固态。同样,这将视情况而定。
-
学习蒙版 -如前所述,学习蒙版是否有任何好处是有争议的。启用此选项将使用更多的VRAM,因此我倾向于将其关闭,但是如果您希望在转换中使用预测的掩码,则应启用此选项。
-
适用于初始化模型的初始化选项。

正如在 培训概述该模型的权重在每次迭代结束时都会更新。初始化是首先设置这些权重的过程。您可以看到这为模型的入门提供了帮助。如我们所知,我们的神经网络将用于什么,我们可以将这些权重设置为一些值,这将有助于模型在生命中有一个快速的开始。 初始化的默认方法是“ he_uniform”。这将从均匀分布中抽取样本。进入不同的初始化方法及其含义不是本教程的目标,但是可以通过本节中提供的选项来覆盖此默认设置。 应当注意,某些模型在内部为模型的某些层设置了初始化方法,因此这些层将不受此设置的影响。但是,对于尚未显式设置此参数的图层和模型,初始化器将更改为选定的选项。 现有的两个初始化器可以一起使用(即,它们都可以启用而不会产生不良影响)。我倾向于同时启用它们。
-
ICNR初始化 -此初始化程序仅适用于高级层。当它们在NN中放大时,标准初始化可能会在输出图像中导致“棋盘”伪影。该初始值设置项试图防止这些伪影。在本文中可以阅读有关此方法的更多信息:https://arxiv.org/abs/1707.02937
-
转换感知初始化 -卷积感知初始化应用于模型中的所有卷积层。该初始值设置项的前提是,它考虑了卷积网络的用途并相应地初始化权重。从理论上讲,这将导致更高的精度,更低的损耗和更快的收敛速度。有关此初始化程序的更多信息,请参见以下文章:https://arxiv.org/abs/1702.06295 注意:此初始化程序启动时会占用更多的VRAM,因此建议从较小的批处理大小开始,启动模型,然后以所需的批处理大小重新启动模型。 注意:此初始化程序不会在启用多GPU模式下运行,因此,如果使用多个GPU进行训练,则应在1个GPU上开始训练,停止模型,然后继续启用多GPU。
-
适用于模型中各图层的网络选项

这里的选项适用于模型中使用的某些图层。
-
亚像素放大-这是在神经网络中放大图像的另一种方法。实际上,它们只是使用不同的TensorFlow操作来完成与默认像素随机播放器层完全相同的工作。我建议只保留此选项,因为它没有任何区别(将来可能会删除)
-
反射填充 -在最终交换中,某些模型(尤其是小人)和较小程度的DFL-SAE在交换区域的边缘周围都有明显的“灰色框”。此选项更改卷积层中使用的填充类型,以帮助减轻此伪影。我只建议为这两个模型启用它,否则我将忽略它。
-
损失 要使用的损失功能。

有多种不同的方法来计算损失,或者让NN识别其在训练模型方面的表现。我将不详细介绍每个可用功能,因为这将是一个漫长的过程,并且在互联网上有很多有关每个功能的信息。
-
损失函数 -最受欢迎的损失方法是MAE(平均绝对误差)和SSIM(结构相似性)。我个人的喜好是使用SSIM。
-
损失的蒙版损失 -此选项决定是否应将不在面部区域内的图像区域的重要性设置为低于在面部区域内的区域的重要性。此选项应始终启用
-
与优化器有关的优化器选项。

优化器控制神经网络的学习速率。
-
学习率 -除模型崩溃(所有图像都变为纯色块,并且损失突增到无法恢复)之外,通常应将其保留下来。与该页面上的其他参数不同,可以为现有模型调整该值。 学习率决定了每次迭代可以向上或向下调整权重的程度。直觉会说学习率越高越好,但事实并非如此。该模型正在尝试学习获得尽可能低的损失值。设置过高的学习率将不断在最低值上下波动,并且永远不会学到任何东西。将学习率设置得太低,模型可能会跌至低谷,并认为它已达到最低点,并且将停止改进。 认为它是走在山下。您想触底,所以您应该一直走下去。但是,下山的路并不总是下坡的,途中有更小的丘陵和山谷。学习速度必须足够高,以能够摆脱这些较小的山谷,但又不能过高,以至于您最终无法到达下一座山峰。
-
模型 这些是特定于每个模型插件的设置:

如前所述,我不会详细介绍特定于模型的设置。这些因插件而异。但是,我将介绍您可能在每个插件中看到的一些常用选项。与往常一样,每个选项都有一个工具提示,可为您提供更多信息。
-
lowmem-一些插件具有“ lowmem”模式。这使您可以运行模型的精简版本,占用较少的VRAM,但以降低保真度为代价。
-
输入大小 -一些插件可让您调整输入模型的输入大小。输入始终为正方形,因此这是输入模型的图像的宽度和高度的大小(以像素为单位)。不要相信更大的投入总是等于更好的质量。这并非总是如此。还有许多其他因素决定模型是否具有良好的质量。更大的输入大小需要成倍地处理更多的VRAM。
-
输出尺寸 -一些插件可让您调整模型所生成图像的尺寸。输入大小和输出大小不必相同,因此某些模型包含升频器,返回的输出图像大于输入图像。
-
培训师 配置设置页面中的最后一个选项卡适用于培训师或“数据增强”选项:

NN需要看到很多很多不同的图像。为了更好地学习人脸,它会对输入图像执行各种操作。这称为“数据扩充”。如注释中所述,标准设置适用于99%的用例,因此只有在知道它们会有什么影响时才进行更改。
-
评估 -评估培训状态的选项。

-
预览图像 -这是在交换窗口的A边和B边的预览窗口中显示的面孔数量。
-
图像增强 -这些操作是在馈入模型的人脸上执行的。

-
缩放量 -在将脸部馈入NN之前将其放大或缩小的百分比量。帮助模型处理错位。
-
旋转范围 -面输入到NN之前顺时针或逆时针旋转的百分比量。帮助模型处理错位。
-
移位范围 -脸部被送入NN之前向左/向右上/下移动的百分比量。帮助模型处理错位。
-
翻转机会 -水平翻转面孔的机会。帮助创建更多角度供NN学习。
-
颜色增强 -这些增强可控制输入到模型中的人脸的颜色/对比度,以使NN对色差更健壮。

这是引擎盖下颜色增强功能的说明(您不会在预览/最终输出中看到它,仅用于演示目的):

-
彩色亮度 -上下调整输入图像亮度的百分比。有助于应对不同的照明条件。
-
颜色AB-在L * a * b颜色空间的A / B比例上调整颜色的百分比量。帮助NN处理不同的颜色条件。
-
Color CLAHE Chance(色彩CLAHE机会) -图像将应用“对比度受限的自适应直方图均衡”的机会百分比。CLAHE是一种对比方法,试图定位对比变化。这有助于NN处理不同的对比度量。
-
颜色CLAHE最大大小 -CLAHE算法的最大“网格大小”。这被缩放到输入图像。较高的值将导致较高的对比度应用。这有助于NN处理不同的对比度量。
对设置进行建模后,请单击“确定”以保存配置并关闭窗口。 注意:点击确定会将选项保存在所有选项卡上,因此请确保仔细检查它们。您可以单击“ 取消”以取消所有更改,或单击“ 重置”以将所有值恢复为其默认设置。
配置
现在您已经准备好了自己的脸,已经配置了模型,现在该开始了! 转到GUI中的“火车”选项卡:

在这里,我们将告诉Faceswap所有内容的存储位置,要使用的内容以及实际开始的培训。
-
面 在这里,我们将告诉Faceswap面的存储位置以及它们各自的路线文件的位置(如果需要)

-
路线A-如果您是戴着口罩训练,或者使用“经向地标”,那么您将需要一个面部路线文件。这将在提取过程中生成。如果该文件存在于您的faces文件夹中,并且名为alignments.json,则该过程将自动将其提取。必须在“面”文件夹中的每个面都在路线文件中有一个条目,否则训练将失败。您可能需要合并多个路线文件。您可以在中找到有关准备路线文件以进行培训的更多信息。提取教程。
-
路线B-如果您是戴着口罩训练,或者使用“经向地标”,那么您将需要一个面部路线文件。这将在提取过程中生成。如果该文件存在于您的faces文件夹中,并且名为alignments.json,则该过程将自动将其提取。必须在faces B文件夹中的每个单个面孔在路线文件中都有一个条目,否则训练将失败。您可能需要合并多个路线文件。您可以在中找到有关准备路线文件以进行培训的更多信息。提取教程。
-
与您将要训练的模型有关的模型选项:

-
模型目录 -将在其中保存模型文件。如果要启动新模型,则应该选择一个空文件夹,如果要从已经开始的模型恢复训练,则应该选择一个包含模型文件的现有文件夹。
-
允许增长 -[仅限NVIDIA]。启用TensorFlow GPU`allow_growth`配置选项。此选项可防止TensorFlow在启动时分配所有GPU VRAM,但可能导致更高的VRAM碎片化和较慢的性能。仅当您在培训方面遇到问题时才启用它(特别是,您遇到cuDNN错误)。
-
培训 培训特定设置:

-
批次大小 -如上所述,批次大小是一次通过模型馈送的图像数量。增加此数字将增加VRAM使用率。批量增加将使培训加速到一定程度。小批量可以提供一种有助于模型概括的法规形式。虽然大批量训练速度更快,但批量大小在8到16之间可能会产生更好的质量。关于其他形式的监管能否替代或消除这种需求,仍然是一个悬而未决的问题。
-
迭代次数-在自动停止训练之前要执行的迭代次数。这实际上仅是为了自动化,或确保一定时间后停止培训。通常,当您对预览的质量感到满意时,您将手动停止培训。
-
GPU- [仅限NVIDIA]-要训练的GPU数量。如果您的系统中有多个GPU,则最多可以利用其中8个GPU来加快培训速度。请注意,这种加速不是线性的,添加的GPU越多,退货的收益就越多。最终,它允许您通过将批处理量分配到多个GPU来训练更大的批处理量。最薄弱的GPU的速度和VRAM总是会成为您的瓶颈,因此在相同的GPU上进行训练时效果最佳。您可以阅读有关Keras multi-gpu的更多信息这里
-
变形为地标 -如前所述,数据是变形的,以便NN可以学习如何重新创建面孔。变形为地标是另一种变形方法,该方法尝试将面从另一侧随机变形为相似的面(即,对于A集,它从B集中找到一些相似的面,并应用变形并进行一些随机化处理)。是否与标准随机变形相比有任何好处/不同,尚待确定。
-
无翻转 -随机翻转图像以帮助增加NN将看到的数据量。在大多数情况下,这很好,但是脸部不对称,因此对于某些目标而言,这可能是不希望的(例如,脸部一侧的痣)。通常,应取消选中该选项,并且在开始培训时当然也应选中该选项。在会话的稍后阶段,您可能要为某些交换禁用此功能。
-
无增强颜色 -Faceswap执行颜色增强(前面有详细介绍)。这确实有助于在A和B之间匹配颜色/照明/对比度,但有时可能不希望如此,因此可以在此处禁用它。增色的影响如下所示:

-
VRAM节省 优化设置以保存VRAM:

Faceswap提供了许多VRAM节省优化功能,这些优化功能使用户能够训练他们原本无法训练的模型。不幸的是,这些选项当前仅适用于Nvidia用户。这些应该是呼叫的最后一个端口。如果您可以在不启用这些选项的情况下以至少6-8的批量进行训练,那么您应该首先这样做,因为所有这些都会带来速度上的损失。可以相互启用所有这些选项,以节省堆栈。
-
内存节省梯度 -[仅限于NVIDIA]-MSG是一种优化方法,可以以计算量节省VRAM。在最佳情况下,培训时间增加20%即可使您的VRAM需求减半。这是您应该尝试的第一个选项。您可以阅读有关“内存节省梯度”的更多信息这里。
-
优化器节省 -[仅适用于NVIDIA]-通过在CPU而非GPU上执行一些优化计算,可以节省相当数量的VRAM。这样做确实以增加系统RAM使用率和降低训练速度为代价。这应该是您尝试的第二个选项。
-
乒乓球 -[仅限NVIDIA]-又称“不得已”。到目前为止,这是最差的VRAM保存选项,但可能足以满足您的需求。这基本上将模型分为两部分,并将一次训练模型的一半。这可以节省多达40%的VRAM,但将花费超过两倍的时间来训练模型。这应该是您尝试的最后一个选择。 注意:启用此选项后,TensorBoard日志记录/绘图功能将不可用。 注意:在模型的两侧都完成训练周期之前,不会显示预览。
-
保存 选项以计划保存模型文件:

-
保存间隔 -将模型保存到磁盘的频率。保存模型时,不会对其进行训练,因此您可以提高该值以在训练时略微提高速度(即,它不等待模型被频繁写入磁盘)。您可能不想将其提高得太高,因为它基本上是您的“故障保护”。如果模型在训练期间崩溃,那么您将只能从上一次保存继续。 注意:如果使用Ping Pong的内存保存选项,则不应将此值增加到100以上,因为这可能会损害最终质量。
-
快照间隔 -快照是模型在某个时间点的副本。如果您对模型的进度不满意,则可以回滚到较早的快照,如果保存文件已损坏并且没有可用的备份,则可以回滚到较早的快照。通常,此数量应该很高(在大多数情况下,默认值应该很好),因为创建快照可能会花费一些时间,并且在此过程完成时,您的模型将无法进行训练。
-
用于显示训练进度预览窗口的预览选项:

如果您使用的是GUI,那么通常您将不想使用这些选项。预览是一个弹出窗口,显示培训进度。GUI将这些信息嵌入“显示”面板中,因此弹出的窗口将仅显示完全相同的信息,并且是多余的。预览在每次保存迭代时更新。
-
预览比例 -弹出预览的尺寸与训练图像的尺寸相同。如果您的训练图像为256像素,则整个预览窗口将为3072x1792。对于大多数显示器来说,这太大了,因此此选项将预览按给定的比例缩小。
-
预览 -启用以弹出预览窗口,禁用以不弹出预览窗口。对于GUI使用,通常不要选中它。
-
写入图像 -这会将预览图像写入faceswap文件夹。如果在无头系统上训练很有用。
-
延时摄影选项,用于生成一组可选的延时摄影图像:

“时间间隔”选项是一项可选功能,通过该功能,您可以查看随着时间推移对固定脸部进行训练的进度。在每次保存迭代时,将保存一张图像,显示在该时间点对所选脸部进行训练的进度。请注意,延时摄影图像占用的磁盘空间量会随着时间推移而堆积。

-
缩时摄影输入A-包含要用于生成A(原始)面时间流逝的面孔的文件夹。仅使用找到的前14张脸。如果您想从训练集中选择前14张面孔,则可以将其指向“ Input A”文件夹。
-
缩时摄影输入B-一个文件夹,其中包含要用于生成B(交换)面的时间间隔的脸部。仅使用找到的前14张脸。如果您想从训练集中选择前14张脸,则可以将其指向“输入B”文件夹。
-
缩时摄影输出 -您想要保存所生成的缩时摄影图像的位置。如果您提供了A和B的来源,但将其留为空白,则默认为您选择的模型文件夹。
-
Global Global Faceswap选项:

这些选项对于Faceswap的每个部分都是全局的,而不仅仅是培训。
-
Configfile-您可以指定一个自定义的train.ini文件,而不使用存储在faceswap / config文件夹中的文件。如果您想在几种不同的良好配置之间进行切换,这将很有用。
-
LOGLEVEL -该级别Faceswap将记录在。通常,应始终将其设置为INFO。仅在开发人员要求时,才应将其设置为TRACE,因为这将大大减慢培训速度并生成大量日志文件。 注意:控制台只会登录到VERBOSE级别。DEBUG和TRACE的日志级别仅写入日志文件。
-
日志文件 -默认情况下,日志文件存储在faceswap / faceswap.log中。您可以根据需要在此处指定其他位置。
锁定所有设置后,请检查它们以确保您满意,然后单击“ 训练”按钮开始训练。
监控培训
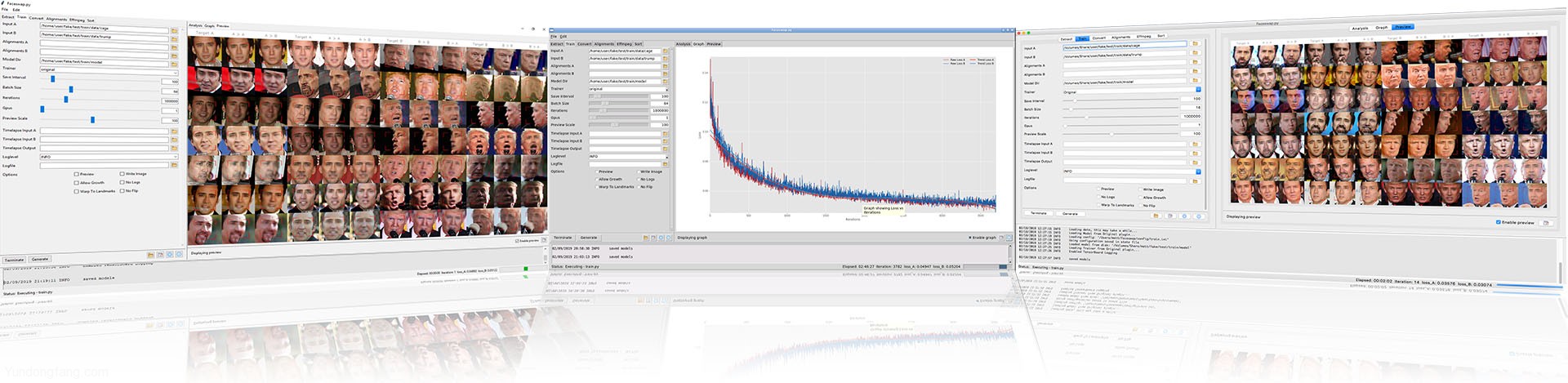
一旦开始训练,该过程将花费一两分钟来构建模型,预加载数据并开始训练。一旦启动,GUI将进入训练模式,在底部放置一个状态栏,并在右侧打开一些选项卡:
-
状态栏 它显示在右下方,并提供当前培训课程的概述。它更新每次迭代:

您无需在此处密切关注损失数。对于换脸,它们实际上是毫无意义的。这些数字给出了关于NN认为其重新创建Face A的程度以及重新创建Face B的程度的想法。但是,我们对模型通过Face A的编码创建Face B的效果很感兴趣。这是一个损失值,因为没有实际的例子可以让NN进行比较。
-
经过的时间-该培训课程已过去的时间。
-
会话迭代次数-在此培训课程中已处理的迭代次数。
-
Total Iterations-此模型的所有会话已处理的迭代总数。
-
损失A /损失B-当前迭代的损失。注意:可能会有多个损耗值(例如,面部,蒙版,多路输出等)。该值是所有损失的总和,因此此处的数字差异可能很大。
-
预览选项卡 可视化模型的当前状态。这表示模型重新创建和交换面的能力。每次保存模型时都会更新:

知道模型是否已完成训练的最好方法是观看预览。最终,这些说明将显示实际交换的外观。当您对预览感到满意时,就该停止训练了。眼部眩光和牙齿等精细细节将是最后要做的事情。一旦定义了这些,通常可以很好地表明培训即将完成。
-
预览将显示12列。前6个是“ A”(原始面)侧,后6个是“ B”(交换面)侧。每组6列分为2组,每组3列。对于以下各列:

-
第1列是输入到模型中的不变面
-
第2列是试图重现该面孔的模型
-
第3列是试图交换面孔的模型
-
这些将以纯色或非常模糊的颜色开始,但随着时间的流逝,随着NN学习如何重新创建和交换脸部而将逐渐改善。
-
不透明的红色区域表示被遮盖的脸部区域(如果使用遮罩进行训练)。
-
如果训练的覆盖率小于100%,您将看到一个红色框的边缘。这表示“交换区域”或NN正在训练的区域。
-
您可以使用右下角的“保存”按钮保存当前预览图像的副本。
-
可以通过取消选中右下角的“启用预览”框来禁用预览。
-
图形选项卡 -此选项卡包含一个显示随时间损失的图形。每次保存模型时都会更新,但是可以通过单击“刷新”按钮来刷新:

您无需太在意此处的数字。对于换脸,它们实际上是毫无意义的。这些数字给出了关于NN认为它如何重新创建Face A以及重新创建Face B的程度的想法。但是,我们对模型通过Face A的编码创建Face B的效果很感兴趣。这是一个损失值,因为没有实际的例子可以让NN进行比较。 损耗图仍然是有用的工具。最终,只要损失减少,该模型仍在学习。该模型学习的速度将随着时间的流逝而降低,因此到最后,可能很难辨别它是否仍在学习。在这些情况下,请参阅“分析”选项卡。
-
根据输出数量的不同,可能会有多个图表可用(例如,总损耗,掩模损耗,面部损耗等)。每个图都显示该特定输出的损耗。
-
您可以使用右下角的“保存”按钮保存当前图形的副本。
-
可以通过取消选中右下角的“启用预览”框来禁用图形。
-
分析选项卡 -此选项卡显示当前正在运行和以前的培训课程的一些统计信息:

-
列如下:
-
图形 -单击蓝色图形图标以打开所选会话的图形。
-
Start / End / Elapsed-每个会话的开始时间,结束时间和总训练时间。
-
批次 -每个工作阶段的批次大小
-
迭代数 -每个会话处理的迭代总数。
-
EGs /秒 - 每秒通过模型处理的面数。
-
当模型不训练时,您可以通过单击右下角的打开按钮并在模型文件夹中选择模型的state.json文件来打开先前训练过的模型的统计信息。
-
您可以使用右下角的“保存”图标将分析选项卡的内容保存到一个csv文件中。
如上所述,损失图对于查看损失是否正在下降很有用,但是当模型经过长时间训练时可能很难辨别。分析选项卡可以为您提供更详细的视图。
-
单击您最近的培训课程旁边的蓝色图形图标,将弹出所选课程的培训图形。

-
选择“显示平滑”,将平滑量提高到0.99,点击刷新按钮,然后放大最后5,000-10,000次迭代:

-
现在,该图已放大,您应该能够知道损失是否仍在下降或损失是否已经“收敛”。收敛是当模型不再学习任何东西时。在此示例中,您可以看到,虽然乍一看似乎模型已经收敛,但仔细检查后,损失仍在下降:

只需按一下GUI左下方的“ 终止”按钮,即可随时停止训练。该模型将保存其当前状态并退出。 通过选择相同的设置并将“ model dir”文件夹指向与保存的文件夹相同的位置,可以恢复模型。通过从GUI文件菜单或选项面板下面的保存图标保存Faceswap配置,可以使此操作变得更加容易。


然后,您可以重新加载配置并继续培训。 可以在“训练”文件夹中添加和删除人脸,但是请确保在进行任何更改之前先停止训练,然后再次恢复。如果您正在使用“经向地标”或使用蒙版进行训练,则需要确保使用新面和移除面更新路线文件。 恢复损坏的模型
有时模型会损坏。可能有多种原因,但这可以通过预览中的所有面孔变为纯色/乱码来证明,并且损耗值急剧上升而无法恢复。 Faceswap提供了可轻松恢复模型的工具。每次丢失值总体下降的保存迭代将保存备份。可以通过以下方式恢复这些备份:
-
转到工具 > 恢复:

-
模型目录 -包含损坏的模型的文件夹应在此处输入:

点击恢复按钮。恢复后,您应该可以从上次备份进行培训。
附件


来源:https://forum.faceswap.dev/download/file.php?id=188